
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- RDBMS
- UMAP
- dementional reduction
- 기초
- 알고리즘
- CNN
- 딥러닝
- ASR
- 캐글
- 정보처리기사
- 소프트웨어 개발
- Python
- 힙정렬
- 자연어처리
- RNN
- 데이터엔지니어
- python기초
- 객체지향
- LangGraph
- 에이전트
- 트랜스포머
- python 기초
- SQL
- 랭그래프
- TTS
- 생성형 인공지능
- 데이터 시각화
- CLIP
- 머신러닝
- Transformer
Archives
- Today
- Total
수달이네 기술 블로그
3. 차원 축소(PCA, t-SNE, UMAP...) 본문
차원 축소
차원의 저주(Curse of Dimensionality)

데이터의 차원이 증가할수록 공간의 부피가 기하급수적으로 커져서 기존에 효과적이던 알고리즘, 분석 방법의 성능이 급격히 떨어지는 현상
- 고차원에선 데이터가 희소하게 분포됨
- 거리 기반 알고리즘(KNN, 클러스터링 등)이 모든 점 사이의 거리가 비슷해짐.
- 데이터를 화면에 표기할 때 차원이 많아도 그리기 힘듦
- 학습에 필요한 데이터도 급격히 증가.
- 위 이유로 차원이 높아지면 예측 정확도, 일반화 성능이 급격히 나빠짐.
- 예를 들어, 10개의 데이터를 표현하기 위해 → 1차원 : 10칸, 2차원 10x10칸, … , 10차원 10^10칸
- 차원이 늘어날수록 공간이 매우 커지는 것도 문제지만, 대부분의 칸이 빈 칸이 된다.(희소성)
차원 축소(Dimensionality Reduction)
고차원의 데이터를 핵심 정보, 구조는 최대한 유지하며 낮은 차원으로 압축하는 기법
- PCA, UMAP, t-SNE등의 방법으로 불필요한 중복 정보, 노이즈를 줄이고 중요 패턴만 남긴다.
- 이를 통해 모델 학습이 안정적이고, 과적합이 완화되며, 차원을 시각화하기 쉬워진다.
PCA(주성분 분석, Principal Component Analysis)

고차원의 데이터를 낮은 차원으로 변환하면서도, 데이터의 분산(정보)를 최대한 보존하는 축소 기법
- 원본 데이터에서 상관관계를 분석해 가장 큰 분산을 가지는 방향(주성분)을 찾는다.
- 공분산 행렬을 분해해 주성분을 찾음
- 이 방향을 기준으로 데이터를 재 투영한다.
- 위 방식을 통해 노이즈를 줄이고 계산 효율이 높아진다.
- 중요한 컬럼 선택, 중요하지 않은 것 날림.
- 시각화, 전처리에 활용된다.
- PCA는 선형 변환 기법이고, 주성분이 서로 직교(orthogonal)한다.
- 별도의 반복 최적화 과정이 없다.
그러나 PCA는 최근엔 잘 사용하지 않는다.
- 선형축만 찾아내 요즘 데이터 분석하여, 비선형 데이터는 패턴을 찾기 힘듦.
- 수십, 수백만 차원의 데이터에서 계산비용이 매우 커짐
t-SNE(t-Distributed Stochastic Neighbor Embedding)
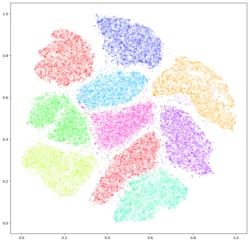
고차원 데이터를 2차원, 3차원으로 줄여 시각화하는 데 자주 쓰이는 차원 축소 기법
- 매니폴드 가정(Manifold assumption)에 기반해 국소적인 구조(근접한 점들의 관계)를 잘 보존
- 고차원 공간에서 이웃한 점들이 가질 확률 분포와 저차원 공간에서 확률 분포가 비슷해지도록 최적화한다.
- t-분포를 이용해 군집 사이의 거리를 더 넓게 벌려주는 효과를 낸다.
- 가까운 점은 더 가깝게 먼 점은 더 멀게 배치하는 방식
- 복잡한 데이터의 잠재적 패턴을 시각적으로 잘 드러낸다.
매니폴드 가정(Manifold Hypothesis)
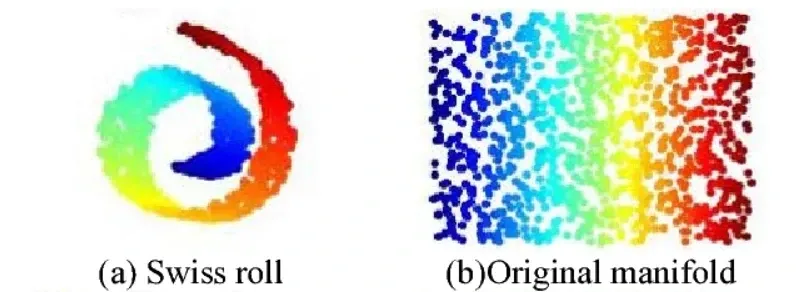
고차원 데이터가 실제로는 훨씬 더 낮은 차원의 매끄러운 곡면(매니폴드)위에 놓여있다고 보는 가정
- 즉, 데이터가 고차원 공간을 가득 채우지 않고, 저차원 구조로 분포한다.
- 복잡해보이는 데이터도 저차원에서의 규칙성, 구조를 더 잘 이해, 처리할 수 있다는 통찰 제공
t-분포를 사용하는 이유

정규분포(가우시안): 가운데가 크고, 멀리가면 값이 너무 빨리 작아져 멀리 떨어진 점을 구별하지 못한다.
t-분포: 가운데는 정규와 비슷하나, 꼬리가 두꺼워 멀리 떨어진 점도0이라 표현하지 않고, 적당히 떨어졌다고 표현(자유도를 이용)
자유도
- 표본 데이터를 가지고 분산을 추정할 때, 실제로 독립하여 변할 수 있는 값의 개수
- 표본 평균을 계산하는 과정에서 하나의 제약조건이 생겨 자유도는 n-1이 된다.
- 데이터 수에서 평균 계산 때문에 묶인 1개를 뺀 것.
- 자유도가 작을 수록 t분포의 꼬리가 두꺼워지고, 커질수록 정규분포에 가까워진다.
- 자유도가 커진다 = 표본수가 많아져 분산 추정의 불확실성이 줄어든다.
UMAP(Uniform Manifold Approximation and Projection)

고차원 데이터를 저차원 공간으로 효율적으로 축소하는 비선형 차원 축소 기법
- 데이터 근접 그래프를 그린 후 보존한다.
- 매니폴드 가정, 위상 공간 이론 적용
- 고차원 공간에서의 이웃관계(근접)을 저차원에서도 유지
- 군집의 형태, 거리, 밀도 정보까지 보존
- t-SNE보다 속도가 빠름
- 전체 구조, 국소 구조를 모두 잘 보존함 (+선형, 비선형 모두 추출 가능)
- 클러스터링, 전처리, 특징 추출, 노이즈 제거 등 머신러닝 작업에 활용됨.
초기값 설정
t-SNE와 UMAP의 초기값 설정(initialization)이 시각화 품질과 신뢰도에 큰 영향을 미친다는 의견이 다수
초기값을 랜덤 초기화가 아닌 PCA로 설정할 경우
- t-SNE 상에서의 안정적인 구조(global structure) 보존, 재현성(reproducibility)이 높아지는 것으로 보고된다.
- UMAP 상에서도 전역 구조를 잘 유지함.
좋은 차원 축소를 위해 알고리즘 뿐 아니라 초기화 방법도 잘 설계해야함.

- 위 그림은 PCA 초기화가 미치는 영향을 나타낸 그림이다.
- random값 초기화를 이용하여 차원축소를 했을 때 데이터가 나뉘고 왜곡된다.
- PCA 초기화를 사용했을 때, 구조가 보존되고, 안정적인 것을 확인할 수 있다.
'AI공부 > 멀티모달' 카테고리의 다른 글
| 6. DINO(Zero-shot Object Detection, DETR, Hungarian matching, Swim Transformer) (0) | 2026.03.18 |
|---|---|
| 5. CLIP모델과 UMAP을 이용한 차원축소 시각화 (0) | 2026.03.17 |
| 4. 차원 축소 시각화(t-SNE, UMAP, initialization: random, PCA) (0) | 2026.03.16 |
| 2. CLIP모델 구현 (0) | 2026.03.14 |
| 0. 멀티모달 개요 (0) | 2026.03.12 |
'AI공부/멀티모달' Related Articles
more
