
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- python기초
- 힙정렬
- 에이전트
- 정보처리기사
- 캐글
- UMAP
- RNN
- 알고리즘
- SQL
- Python
- 트랜스포머
- dementional reduction
- RDBMS
- 자연어처리
- CNN
- CLIP
- 랭그래프
- ASR
- 머신러닝
- LangGraph
- 딥러닝
- python 기초
- TTS
- Transformer
- 생성형 인공지능
- 기초
- 데이터엔지니어
- 소프트웨어 개발
- 객체지향
- 데이터 시각화
- Today
- Total
수달이네 기술 블로그
5. 영상트랜스포머의 응용 본문
🔍영상 패치 임베딩
CNN은 영상의 픽셀 단위가 입력의 단위이다.(필터를 적용하여 한 픽셀마다 윈도우 식으로 옮겨나감)
트랜스포머는 픽셀단위가 아닌 그것보다 큰 패치단위로 입력한다.(마치 텍스트에서 사용하던 워드단위를 이미지에도 적용한 것)
영상패치임베딩이란, 이미지를 작은 패치 단위로 분할하고 각 패치를 고정된 차원의 벡터로 변환하는 과정이다.(1D임베딩)
- 작은 지역적 특징을 잘 포착한다.
- 패치간의 관계를 모델에 반영하기 쉽다.
- 셀프 어텐션으로 관계를 파악
- CNN은 거리가 멀면 그 관계를 파악할 수 없다.
- 이미지의 전역적, 지역적 특징을 모두 고려하는 효과를 얻는다.
- 큰 이미지를 다루는데에도 효율적이다.
임베딩 패치 단계
- 단어처럼 이미지 나누기
- 분할된 이미지는 N차원 공간에 매핑
영상을 패치로 나누기
단어 삽입의 경우 문장의 구분선은 분명하다. 그러나
영상, 사진의 경우 구분선이 없다. 따라서 일부 연구자는 2차원 사진을 1차원으로 직접 가져오지만 리소스가 과도하게 소모된다.
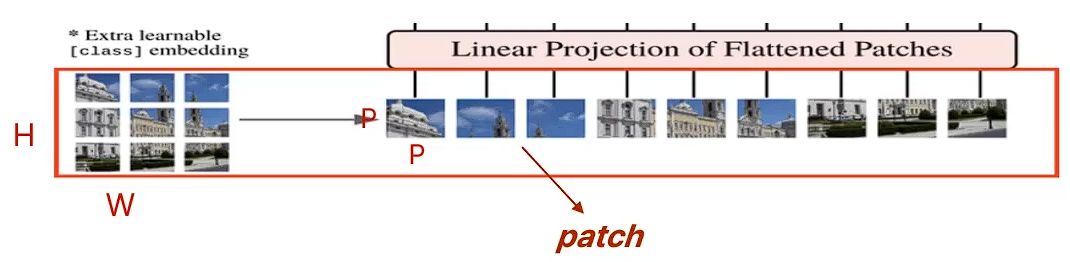
방법
- 이미지 입력:[H(높이), W(너비), C(채널)]
- 패치 이미지: [P,P,C]
- 패치 번호: N = H * W / (P * P)
- 이미지를 N개의 숫자 P*P패치 이미지[N,P,P,C]로 분할
N차원 공간에 매핑

위로 분할한 이미지를 평평하게 만든다.
D= PPC를 구하면 이미지의 치수는
N,D로 표현할 수 있으며, 이 이미지를 1D패치로 매핑한다.
Vit모델(vision transformer)
Vit의 목표는 영상분류(Image Classification)이다.
- input으로 새로운 이미지가 입력되었을 때 이 영상을 분류함.

해당 레이어를 여러 겹으로 사용 가능하다
- 최고의 성능을 내는 레이어를 확인하고 설정해야한다.
클래스 임베딩

트랜스포머의 인코더의 출력상태가 영상 표현으로 사용됨.
포지션 임베딩
순서대로 각각의 패치들을 임베딩하여 트랜스포머 인코더에 넣어준다. 각각의 패치는 순서가 중요하고, 앞에 포지션을 주어 위치를 보존한다.
성능
CNN기반 모델과 비교하여 다른 특징을 가지고, 많은 작업에서 뛰어난 성능을 보임
- 대규모 데이터 셋에서 사전 훈련했을 경우 작은 데이터셋으로 전이학습 시킬때 좋은 결과를 얻을 수 있고, 이로인해 소량의 데이터로 강력한 이미지 인식 모델을 구축할 수 있다.
한계
계산비용: VIT는 Trnasformer모델을 사용하기 때문에 CNN에 비해 계산 비용이 높으며 입력 이미지를 패치 단위로 분할하고 적용하는 과정이 연산량이 크다.
데이터 양과 크기: 사전 훈련을 하기 위해서 대규모 데이터셋이 필요하고, 과적합 문제가 발생할 수도 있다,. 따라서 작은 데이터 셋에서 사요하기 위해선 전이학습을 사용해야한다.
이미지 크기 제한: 작은 패치로 분할하기 때문에 큰 이미지를 다루기 어렵고, 패치 크기를 잘 설정해야한다.
기본적으로 ViT를 사용하고 이후 파인튜닝을 한다.
U-Net
transformer는 아니지만 transformer와 긴밀한 관계를 가진다.
image Segmentation을 목표로 한다(영상 내 세부 분류: MRI, CT등에서 암 등 추출)

U자형 구조를 가졌다.
인코더와 디코더로 구현된 네트워크로 오토 인코더와 비슷한 모양을 띈다.
그러나 UNet은 skip(Residual) connection이라는 특징을 가지는데
- 왼쪽위의 시그널이 아래로 내려갔다 다시 올라가는 형식을 띄는데 여러 정보를 유지하기 힘들지만
- skip connection으로 유지한다.
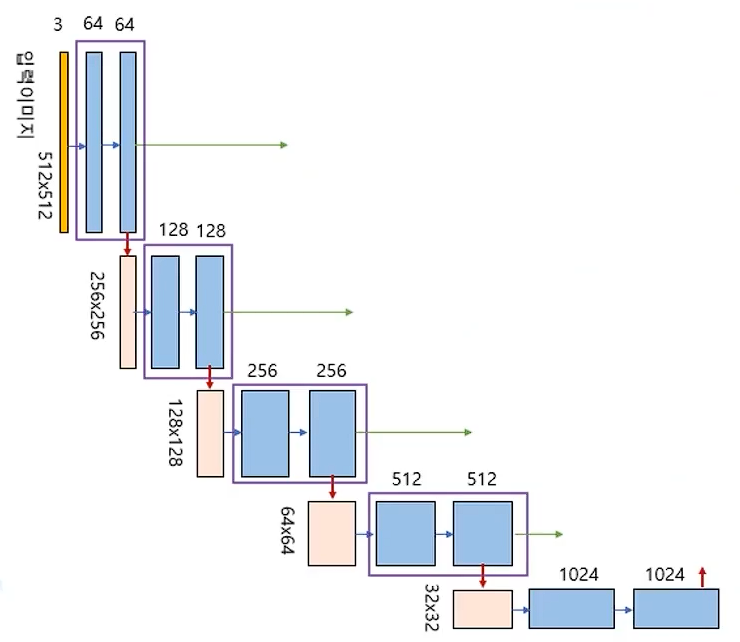
- 인코더: 풀링 레이어의 공간 차원을 줄임
- 디코더: 오브젝트의 디테일과 공간 차원을 복구
- 스킵 커넥션: 인코더와 디코더의 바로가기 연결(세부사항 복구)
인코더
디코더
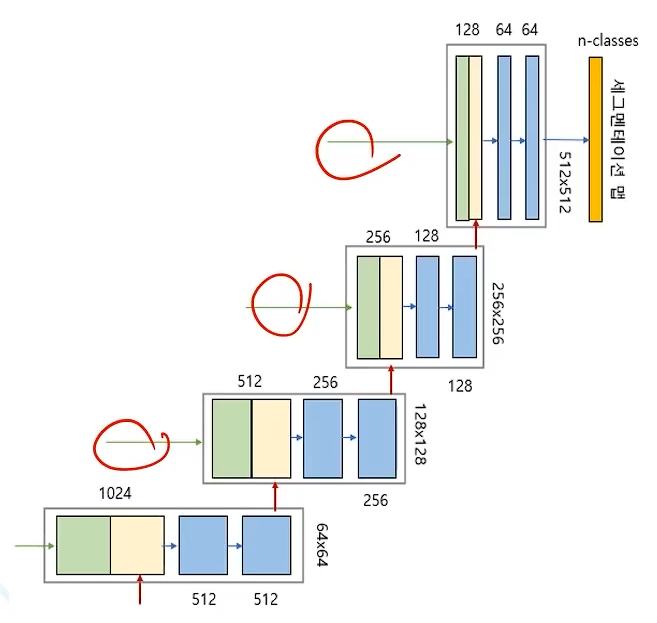
두개의 맵을 서로 합쳐서 저차원 뿐 아닌 고차원의 정보도 이용
장점
세그먼테이션에 적합한 구조
U자형 구조: 영상의 공간적 정보 보존, 크기 절감, 특징 추출에 유용
데이터 부족 문제 해결: 작은 데이터 셋에서 잘 작동
다양한 응용 분야: 자율주행 자동차, 얼굴, 사물인식등 분야에서 사용됨.
멀티헤드어텐션 in computer vision

소프트 어텐션

가중치가 적용된 특징 표현을 얻기 위해 입력데이터의 가중치 평균
위 그림처럼 그라데이션을 줄 수 있음.
하드 어텐션

가장 중요한 데이터를 선별하여 모델의 입력으로 사용하기 위해 입력 데이터를 선택하는 것을 말함.
위 그림처럼 0 혹은 1로 설정한다.
영상 트랜스포머 응용
영상 분류
CNN과 함꼐 사용된다.
ViT는 입력 영상을 청크로 전달하고 이런 청크를 시퀀스로 트랜스포머 인코더에 전달한다.
기존 CNN보다 더 나은 해석 가능성을 제공한다.
물체감지
트랜스포머를 활용해 입력 이미지를 패치로 분할하고 각 패치에 대해 객체를 감지하고 분류하는데 사용
'학교공부 > 생성형 인공지능' 카테고리의 다른 글
| 7. 생성형 인공지능(GAN, VAE, Diffusion 모델 등) (0) | 2025.10.15 |
|---|---|
| 6. BERT와 GPT (0) | 2025.10.12 |
| 4. 트랜스포머 및 Self Attention (1) | 2025.09.27 |
| 3. CNN(Convolution Neural Network) (0) | 2025.09.19 |
| 2. 재귀 신경망(RNN) (0) | 2025.09.10 |
