
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- CLIP
- ASR
- 데이터엔지니어
- Transformer
- 머신러닝
- 캐글
- Python
- RNN
- python 기초
- 딥러닝
- RDBMS
- 생성형 인공지능
- 정보처리기사
- 알고리즘
- 소프트웨어 개발
- TTS
- 객체지향
- 데이터 시각화
- 트랜스포머
- LangGraph
- SQL
- 랭그래프
- 자연어처리
- CNN
- 힙정렬
- 기초
- python기초
- UMAP
- 에이전트
- dementional reduction
- Today
- Total
수달이네 기술 블로그
4. 트랜스포머 및 Self Attention 본문
🔍워드 임베딩(Word embedding)

단어를 고차원 벡터 공간에서 밀도가 높은 벡터로 표현하는 NLP기술
- 고차원 벡터공간: 다차원으로 양이 많다는 의미로, 의미를 찾기 쉽지 않은 공간
- 밀도가 높은 벡터: 유사도등의 워드의 밀도를 축약하는 임베딩의 첫번째 단계
- 이후엔 self-attention등의 기술등을 사용해 상호연관성을 심도있게 파악
단어간의 의미관계를 포착하하여 유사한 단어가 유사한 벡터표현을 가질 수 있도록 하고, 모델이 단어의 문맥과 의미를 효율적으로 학습하도록 한다.
- man, woman은 성별이라는 것에서 서로 연관되어있음.
단어 표현 방법(Representation)
단어를 숫자 벡터로 변환하여 머신러닝 알고리즘이 텍스트 데이터를 처리하고 이해할 수 있도록 함(다양하게 처리할 수 있다)
- One-hot encoding
- Bag-of-Words(BoW)
- Term Frequency-Inverse Document Frequency(TF-IDF)
- Word2Vec
- Global Vectors for Word Representation(GloVe)
- Fast Text
- Contextual Word Embedding(e.g., ELMo, BERT, GPT)
Representation이 잘되면 Learning이 많이 결정되고, Learning이 잘 일어나며, 처리도 잘된다.
One-Hot Encoding(원-핫 인코딩)
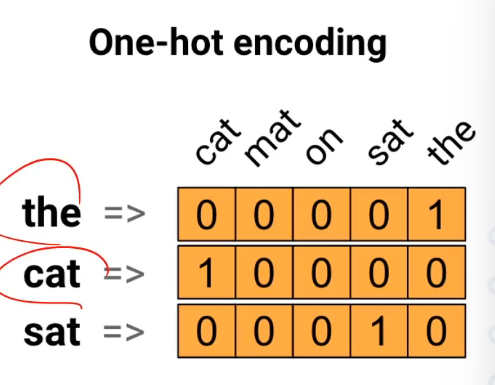
범주형 데이터를 숫자로 표현하기 위해 NLP및 머신러닝에서 널리 사용되는 기술
그 단어에 해당되는 것만 1로 나머지 0
- 간단하지만 의미론적 관계가 부족하고 대규모 어휘의 경우 계산이 비효율적이다.
Bag-of-Words

각 단어의 빈도를 계산해 문장을 벡터로 변환하는 작
- 어순, 문맥은 무시되고 단어의 발생 여부만 중요함.
- 벡터는 텍스트 데이터를 고차원 적인 벡터로 표현함,
- 단순성, 효율성이 뛰어나지만, 의미관계는 포착하지 못한다.
Term Frequency-Inverse Document Frequency(TF-IDF)

말뭉치에서 상대적으로 드문 단어에 높은 가중치를 할당할 수 있다.(특정문서에서 단어의 의미파악) - Bag of Word의 진화된 방식
용어빈도(TF): 문서에서 단어가 얼마나 자주 나타나는지

- 나오는 빈도를 얼마나 나오느냐 직설적으로 나타냄
역문서빈도(IDF): 전체 말뭉치에서 단어가 얼마나 드물거나 고유한지

- 로그 함수를 통해 너무 많이 들어간것은 줄이고, 적게 나온것의 비중을 늘리는 방식
Word2Vec

단어를 고차원 공간에서 조밀하고 연속적인 벡터로 변환한다.
스킵그램(Skip-gram)및 연속 단어 가방(CBOW)과 같은 신경망 아키텍처를 사용하여 대상 단어가 주어지면 문맥 단어를 예측하거나 그 반대로 예측하여 단어 표현을 학습함.
단어간의 의미관계를 캡처하여 비슷한 의미를 가진 단어가 비슷한 벡터표현을 가질 수 있도록 함.
- 단어의 의미론적 관계, 단어유추 가능
GloVe
전체 말뭉치에서 글로벌 단어 동시 발생 통계와 행렬 인수분해를 결합하여 단어 표현을 학습함.
GloVe는 단어를 고차원 공간에서 조밀하고 연속적인 벡터로 표현하여 단어 간의 의미론적 관계와 구문론적 관계를 모두 포착

- 기존 카운팅 기반 방법의 한계를 극
FastText
문자수준 n-그램인 하위 단어 임베딩의 합으로 단어를 나타냄.

어휘에서 벗어난 단어를 처리하고 형태학적으로 풍부한 언어의 의미를 보다 효과적으로 포착 가능
- 희귀, 철자가 틀린단어를 표현, 단어 구조가 복잡한 언어의 경우 더 나은 단어 임베딩 가능
Contextual Word Embedding(e.g., ELMo, BERT, GPT)
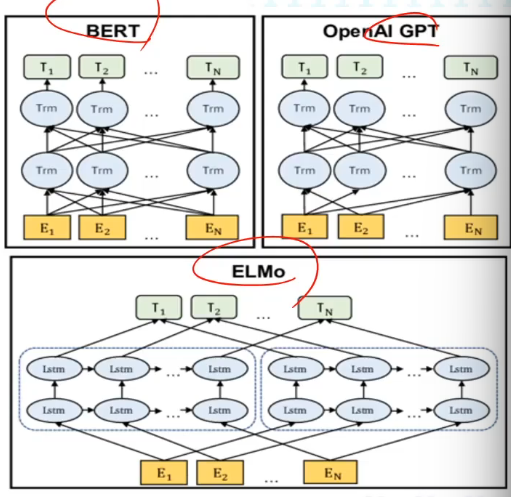
문장, 문서 내에서 주변 문맥을 기반으로 단어의 의미를 캡처
- 문맥에 따라 달라지는 동적 임베딩 생성 가능
- 이러한 임베딩은 단어의 문맥적 뉘앙스를 포착하여 모델이 단어의 의미와 관계를 보다 효과적으로 이해할 수 있도록 지원함.
🔍Self-Attention(자기 주의)
각 요소를 처리할 때 모델이 입력 시퀀스의 다른 부분에 집중할 수 있도록함.
- 확장된 도트-프로덕트 주의라고도 함
- 어디에 Attention(주의)를 주고 어디에 덜 주느냐를 신경씀
외부 요소에 초점을 맞추는 기존 Attention메커니즘과 달리, 자기 주의는 모델이 입력 시퀀스 자체 내에서 종속성과 관계를 설정할 수 있게 함.
- 모델 내에서 self-Attention하되 강도의 차이가 존재.
NLP의 맥락에서 자기 주의는 문장 내 단어 간의 관계를 이해하고, 장거리 종속성을 효과적으로 파악하기 위해 BERT 및 GPT와 같은 트랜스포머 기반 모델에서 널리 활용된다.
자기주의는 관련 단어에 주의를 기울이고 문맥상 중요성을 학습함으로써 모델이 언어번역, 감정 분석, 질문 답변 등 다양한 언어 작업에서 탁월한 능력을 발휘할 수 있도록 지원함.
초기화

입력된 베겉의 집합을 만들어 세개의 학습 행렬(쿼리, 키, 값)을 생성한다.
- Information Retrival : 키값을 주었을 때 value를 찾음.
- QKV로 association했더니 잘 맞아 떨어졌음.
점수 계산

각 입력 벡터에 대해 관심도 점수는 해당 쿼리 벡터와 다른 모든 입력의 키 벡터 사이의 내적을 취하여 계산되며, 현재 입력과 각 입력의 관련성을 측정한다.
크기 조정
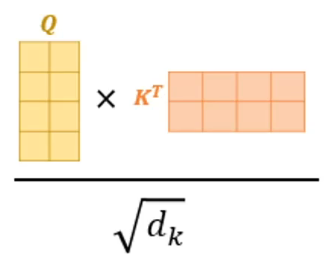
실제 어텐션 점수는 쿼리 벡터 차원의 제곱근으로 나누어지고, 크기 조정은 매우 큰 도트 곱을 방지하여 학습중에 주의 메커니즘을 안정적으로 만드는데 도움을 준다.
softmax적용

확장된 주의 집중도를 소프트맥스 함수를 통과시켜 0~1로 정규화 시키고, 1로 합산되는 주의 집중도 가중치를 생성한다.
Context 벡터

어텐션 가중치는 값 벡터의 가중치 합계를 계산하는데 사용된다. 이 단계에서 입력 시퀀스에서 가장 관련 성이 높은 정보를 강조한다.
가중합에서 얻은 context벡터는 주어진 입력 벡터에 대해 스케일링된 도트-프로덕트 주의메커니즘으로 출력한다.
SelfAttention 연산 과



위와 같이 구현할 수 있다.
🔍Attention mask(주의 마스크)

마스크는 어텐션 계산 중 입력시퀀스에서 어떤 위치에 주목할 수 있는지 제어하는 메커니즘 역할을 한다.
- 값의 가중치 합계를 계산하기 전에 어텐션 점수에 적용되어 특정 위치를 효과적으로 마스킹하고, 용소의 하위 집합으로 주의를 제한한다.
- 단어를 예측할 떄 미래를 보고 예측하지 못하도록 만들기도 함.
Self Attention 장점
- 장거리 종속성 파악특히 복잡한 어순과 종속성을 가진 언어의 문맥 이해에 도움을 줌,
- 모델이 시퀀스에서 멀리 떨어져 있는 요소 간의 관계를 포착할 수 있게 해줌.
- 상황에 맞는 유연성있는 이해
- 각 요소가 입력 시퀀스의 다른 부분을 고려해 표현을 구성할 수 있도록 해줌.
- 병렬처리
- 시퀀스를 순차적으로 처리하는 반복모델과 달리 self-attention 메커니즘은 쉽게 병렬화 할 수 있으며, 이로인해 학습 및 추론이 빠르고 효율적임.
- 가변 길이 시퀀스의 효율적인 처리
- 다양한 길이의 입력 시퀀스 상에서 잘 작동함.(멀티헤드로 처리)
- 계층 구조 관계
- 여러 세부 수준에서 작동하여 로컬, 글로벌 종속성을 파악할 수 있다.
- 확장
- self-attention 계산 비용은 시퀀스 길이에 따라 기하급수적으로 늘어나지만, RNN CNN의 기하급수적 증가에 비해 관리가 쉽다.
- Pre-traning이 가능하다사전 학습된 모델을 특정 다운스트림 작업에 맞게 미세조정하여 최고의 결과를 얻을 수 있음.
- 트랜스포머 등의 self-attention기반 아키텍처는 대규모 텍스트 코퍼스를 대상으로 대규모 모델을 사전학습하는데 효과적
- Multi-modal 앱
- Self-Attentino은 NLP에만 국한되지 않고, 다른 데이터 유형을 처리할 수 있음.
- 해석 가능한 attention
- 사용자가 모델이 특정 예측을 하는 이유를 이해할 수 있도록 도와주는 해석가능한 어텐션 가중치를 제공함.
🔍Multi-Head Attention
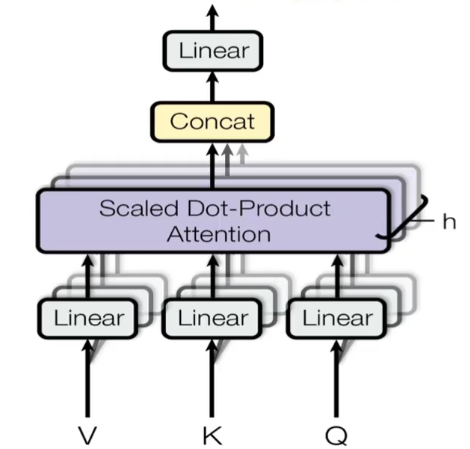
각각 어텐션 헤드에 해당하는 여러 쿼리, 키 및 값이 투영된 집합.
각 헤드에서 생성된 Attention Score는 뚜렷한 패턴 관계를 포착해 다양한 컨텍스트 구조에 대한 모델의 이해를 강화
각 헤드에 대한 Attention Score를 계산하고 출력을 연결한 후 선형적으로 변환해 최종 다차원 표현을 생성한다.
- 긴 문장, 비디오 등 긴 맥락에서 사용하면 좋음.
- 여러 헤드가 하나의 작업을 함.
장점
- 빠른 연산: 각 헤드의 Attention Score를 병렬로 계산하여 모델이 다양하고 복잡한 패턴을 동시에 캡처하여 프로세스 속도가 크게 빨라짐
- 상황별 이해도 향상: 로컬, 글로벌 종속성을 모두 파악하는데에 탁월하므로 컨텍스트 이해에 효과적임 이는 다양한 측면에서 동시에 집중 가능하므로 포괄적 맥락 이해로 이어짐.
- 향상된 성능: 다양한 관계를 학습함으로써 순차 데이터를 처리하는 모델의 능력을 향상시키고, 종속성과 뉘앙스를 효율적으로 포착
- 확장 가능성: 모델의 계산시간을 늘리지 않고도 크고 복잡한 시퀀스 처리 가능
- 적용 가능성: 전문화된 기능을 동시에 적응적으로 학습 가능
- 효율적 하드웨어 활용도: 최신 gpu, tpu등은 병렬연산에 최적화 되어있음.
- 유연성


64차원 단어 임베딩의 각 세트에 대해 Scaled Dot-Product Attention연산
마지막 단계에서 결과 출력이 연결되고, 512차원의 컨텍스트 임베딩 벡터 생
🔍트랜스포머 아키텍처

트랜스포머 모델의 전체 아키텍처는 인코더, 디코더로 이루어져 있음
인코더
멀티헤드 어텐션, 위치별 피드 포워드 네트워크, 잔여 연결 및 레이어 정규화(Norm)으로 구성된 레이어 스택
멀티헤드 셀프 어텐션
- 하위 레이어는 입력 요소간의 자체 Attention Score를 계산하여 모델이 시퀀스 내 여러 위치의 중요도에 가중치를 부여할 수 있도록 함
위치별 피드포워드 네트워크
- 각 포지션의 표현은 완전히 연결된 피드 포워드 신경망을 통해 독립적으로 변환됨.
디코더
인코더와 유사하지만 마스크 멀티헤드 어텐션 기능이 추가됨.
마스크 멀티 헤드 셀프 어텐션
- 디코딩 중에 자동 회귀 속성을 유지하면서 포지션이 후속 포지션에 영향을 주지 않도록 함.
- 문장의 빈공간을 추론하도록 마스크를 씌움
멀티헤드 인코더-디코더 어텐션
- 인코딩된 입력 시퀀스를 처리하여 모델이 타깃 시퀀스를 생성하는 동안 소스 컨텍스트를 고려할 수 있도록 함.
ADD&Norm
- 합과 정규화를 통해 전체적으로 디코더를 완성한다.
포지셔널 인코딩
트랜스포머는 병렬로 동시에 들어오므로 위치 정보를 따로 고려하지 않는다. 따라서 시퀀스의 요소 순서를 전달하기 위해 입력 임베딩에 위치 인코딩을 추가한다.
- 이러한 위치 인코딩은 모델에 입력되기 전에 입력 임베딩과 결합된다.
선형(Linear), 소프트맥스(Softmax)함수
디코더는 각 단계에서 토큰을 예측하여 최종 목표 시퀀스를 생성하며, 출력은 단어에 대한 확률 분포를 생성하기 위해 소프트맥스 활성화 과정을 통과함.
- Linear로 이전까지 비선형이었던 출력을 선형으로 만들고 소프트맥스로 0~1로 정규화
'학교공부 > 생성형 인공지능' 카테고리의 다른 글
| 6. BERT와 GPT (0) | 2025.10.12 |
|---|---|
| 5. 영상트랜스포머의 응용 (0) | 2025.10.09 |
| 3. CNN(Convolution Neural Network) (0) | 2025.09.19 |
| 2. 재귀 신경망(RNN) (0) | 2025.09.10 |
| 1. 생성형 인공지능이란? (ChatGPT, 생성형 인공지능, 인지인공지능과 차이점, 언어 및 영상 생성, 언어 생성 방법) (0) | 2025.09.07 |

