
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- CLIP
- 자연어처리
- LangGraph
- 정보처리기사
- 소프트웨어 개발
- 힙정렬
- CNN
- python 기초
- 객체지향
- RDBMS
- 캐글
- SQL
- 머신러닝
- ASR
- 알고리즘
- 딥러닝
- 기초
- 생성형 인공지능
- Transformer
- TTS
- dementional reduction
- 랭그래프
- python기초
- 트랜스포머
- 에이전트
- RNN
- 데이터엔지니어
- UMAP
- Python
- 데이터 시각화
- Today
- Total
수달이네 기술 블로그
1. 생성형 인공지능이란? (ChatGPT, 생성형 인공지능, 인지인공지능과 차이점, 언어 및 영상 생성, 언어 생성 방법) 본문
1. 생성형 인공지능이란? (ChatGPT, 생성형 인공지능, 인지인공지능과 차이점, 언어 및 영상 생성, 언어 생성 방법)
슬픈 수달이 2025. 9. 7. 03:23위의 사이트는 생성형 AI의 개념, 최신 개발 정보를 제공한다.
🔍ChatGPT란?
OpenAI에서 개발한 초거대 언어모델(LLM)
모델: 트랜스포머 Decoder모델인 생성형 사전 학습 트랜스포머
- Generative(생성형)
- Pre-trained(사전학습)
- Transformer(자연어를 처리하는 기술
GPT전 모델은 BERT(Biderectional Encoder Representations from Transformers)
사용자 query를 기반으로 텍스트를 생성한다.
기능
- 현재 있는 지식을 답하는 형식.
- 번역.
🔍Architecture
트랜스포머
- 글자를 번역한다는 의미
- CNN(Convolutional Neural Net)보다 강력한 모델
디코더
- 일반적으로 인코더와 연결해서 사용
- GPT에서는 인코더로 훈련시킨 것을 디코더로만 사용함.
Masked Multi-Head Self-Attention기반
- 트랜스포머의 기본 알고리즘의 핵심
- 문장을 자르는 각각이 하나의 헤드라 했을때 길어지면 Multi-Head
- 훈련시킬 때 문장에서 일부분을 가려주는 Masked
GPT3.5기반
- Larger input size(토큰수: 2048)
- Larger model size(레이어: 96)
훈련 방법
대규모 데이터 셋(포털사이트 인터넷)를 이용해 인코더에 집어넣어 사전학습
강화학습을 통한 사용자 피드백(RLHF)로 미세조정(Fine-tuning)된다.
- 미세조정이 매우 중요
- Masked 의 질문지가 매우중요
한계
정보, 자료가 2021년에 제한되어 있음.
해당 근거로 답변하지만 사실에 근거하지 않는 부정확한 답변을 생성할 수 있다.
불확실한 query가 제공될 경우 ChatGPT는 추측을 시도한다.
- 최신의 데이터, 지속적인 파인튜닝이 관건이므로 큰 회사가 주도권을 가짐
🔍생성형 인공지능이란?
텍스트, 이미지, 음악등의 콘텐츠 생성을 중점으로 둔 AI의 분야(ChatGPT, VEO등)
종류
이미지: GAN(Generative Adversarial Networks)또는 오토인코더 (Autoencoder)를 사용하여 실제 이미지를 생성
텍스트 : 순환신경망(RNN)이나 트랜스포머(Transformer)를 사용하여 유용한 텍스트를 생성
비디오: 3D Convolution Neural Network나 GAN을 사용하여 동영상을 생성할 수 있음.
오디오: 1D Convolution Neural Network나 GAN을 사용하여 오디오를 생성할 수있음
구성요소

인코더(Encoder): 입력을 해석, Contextual Information생성.
디코더(Decoder): Contextual Information에서 출력을 생성.
🔍생성형 AI 네트워크의 종류와 구조
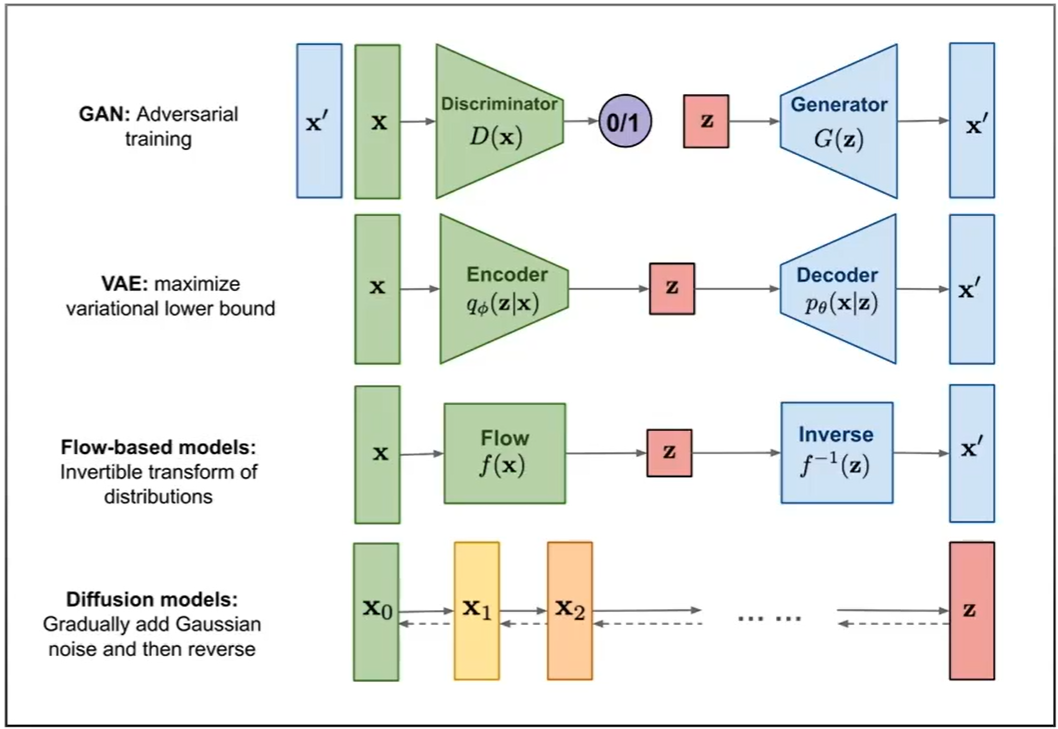
GAN: 판별기와 생성기로 구성
- 판별기와 생성기가 서로 경쟁하며 생성하는 구조
VAE(Variation Autoencoder): 표준 인코더-디코더 아키텍처 판별기
- 이미지를 하나당 확률분포로 매핑
- 완전히 생성하기보단 노이즈 제거 속성 추가 등을 하는데 효과적
Flow-based Model: 디코더는 인코더의 역함수
- 미리정해진 목적지로 flow를 따라가도록 학습
Diffusion Models: 노이즈 생성, 노이즈 제거 수행
- 확산(노이즈 생성) 과정으로 목표 까지 도달
생성형 인공지능의 문제점
데이터셋: 데이터가 충분하지않거나, 품질이 좋지 않으면 생성효과에 큰 영향을 준다.
- 데이터 증강, 전이학습등으로 문제를 줄일 수 있다.
보안, 윤리적 문제등: 인간을 죽이는 방법 등을 묻거나, 보이스 피싱에 사용되는 등.
- 생성형 인공지능은 법의 규제를 받아야한다.(그러나 flexible해야함)
🔍인지(cognitive) 인공지능과의 차이점
인지인공지능
컴퓨터가 인간의 사고, 인지과정을 시뮬레이션 하는 방법을 주로 연구
- 지능적인 의사 결정과 문제 해결을 학습, 추론, 언어 이해, 지식 표현 및 기타 기술적 수단을 통해 이루어진다.
- 데이터 마이닝, 머신러닝, 자연어처리등을 통해 작업을 수행한다.
- 자율 자동차 등
인지 인공지능의 구성요소
지식표현: 지식을 설명, 정리하고, 지식간의 추론 및 사용을 지원한다.
학습: 방대한 양의 데이터에서 패턴을 학습하고 자체 모델을 지속적으로 최적화한다.
자연어처리: 컴퓨터가 자연어로 인간의 의사 소통을 이해하고 처리할 수 있도록 지원한다.
컴퓨터 비전: 디지털 이미지 및 비디오에서 객체에 대한 인식 및 분석을 수행한다.
추론 및 의사 결정: 기존 정보를 기반으로 추론하고 의사결정하여 최상의 솔루션을 제공한다.
응용
고객서비스: 사용자와 상호작용, 음성, 텍스트로 도움말 제공
지능형 검색: 사용자 요구에 따라 방대한 데이터에서 관련 정보를 확보
번역: 자연어를 다른 자연어로 번역
이미지 분석: 종양, 병과 같은 의료 이미지를 분석, 판단
자율주행: 비전 기술, 센서를 사용하여 차량 이동 관리
인지 vs 생성
목적에 차이가 있다.
- 인지: 인간과 같은 인지능력을 발휘할 수 있는 시스템 개발이 목표
- 생성: 이미지, 텍스트등 데이터를 생성하는 시스템 개발이 목표
🔍언어생성
컴퓨터 프로그램을 통해 자연스러운 텍스트를 생성하는 프로세스
- 자연어처리 분야의 하나
- 질의응답, 챗봇,등에 널리 사용됨
- 모르코프 체인, 순환신경망, 트랜스포머등이 사용됨.
자연어 생성 네트워크
딥러닝 기반 접근 방식, 신경망을 모델링 하여 언어의 법칙, 특징을 학습하여 텍스트 생성
- 신경망 생성 모델링의 장점
- 문맥 정보를 처리
- 자연스럽고 유창함.
- 표현력이 풍부한 텍스트를 생성할 수 있음.
- 수동으로 설계된 규칙이 없음.
신경망 기반 언어생성 모델 종류
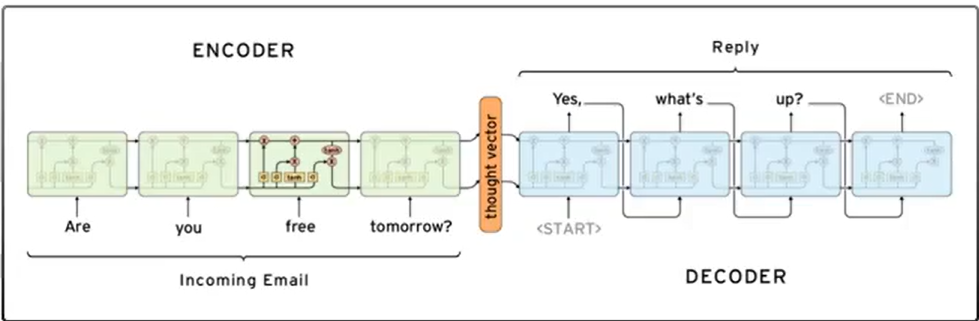
LSTM(Long Short-Term Memory): 인코더에서 자연어를 처리, 디코더에서 자연어를 생성
- 긴 문장에서 RNN보다 나으나 너무 길면 한계있음.
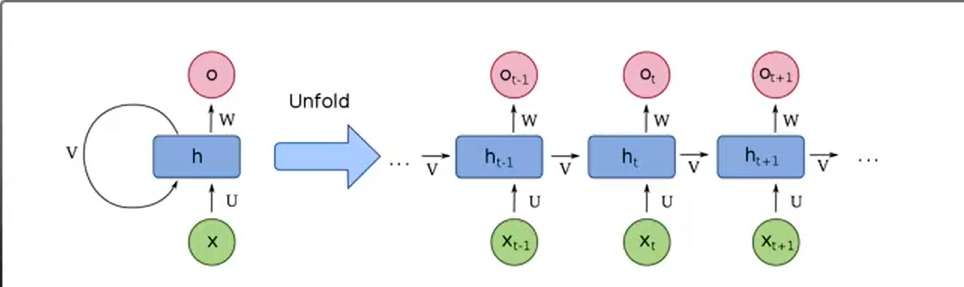
RNN(Recurrent Neural Network): 언어의 순서에 의해 자기가 재귀적으로 문제를 해결
- 긴 문장에서 한
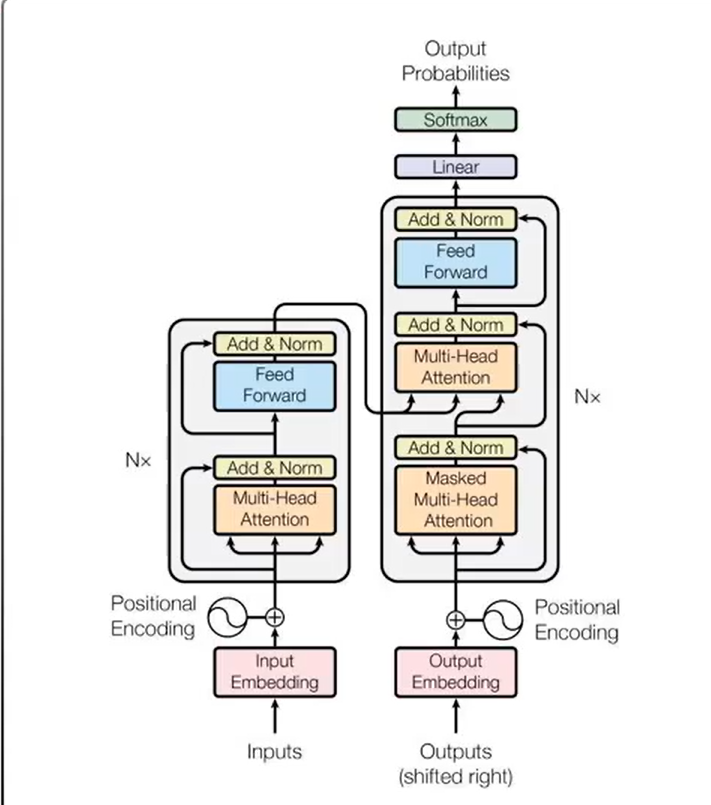
Transformer: 모든 입력 토큰에 문맥 관계를 생성하는 멀티 헤드 셀프 어텐션을 사
- 포지셔널 인코딩(워드별로 나열), self attention(상관관계 찾기)등등…
🔍이미지 생성
입력 이미지와 출력이미지 사이의 매핑 관계를 학습하도록 훈련된 신경망 모델 사용
- GAN, VAE등이 있다.
이미지 생성 모델 종류

GAN: 이미지 생성을 담당하는 생성기(Generator)와 생성된 이미지의 진위 여부를 판단하는 판별기(Discriminator)의 두가지 신경망으로 구성됨.
- Latent Vector같은 랜덤 넘버를 집어넣어 이미지를 생성하고, 실제 이미지와 비슷하게 나오도록함.
- 이 나온걸 판단하는 판별자가 생성한것이 실제 이미지랑 헷갈려 버리면 yes로 헷갈리지 않으면 no로 보냄,
- 따라서 이 두 모델의 균형이 중요

VAE: 입력 영상의 잠재변수 분포를 학습한 다음 이 분포를 기반으로 새 이미지를 생성
- 이미지를 넣고 잠재변수 분포로 만들어 버린후 해당 이미지를 다시 생성하는 것.
- 원래 목적은 같은 걸 생성하는 것이지만, 이것에 노이즈를 제거한다던가. 다른 property를 제공하는 등으로 사용
🔍언어 생성 방법
언어모델 제작 단계
- 데이터셋 선택
- 입력 텍스트 전처리
- 언어모델 선택
- 모델 훈련
- 모델 평가
데이터셋
텍스트 코퍼스(Text Corpus): 언어생성을 위한 데이터 집합
- 여러 문장으로 구성되어 클래스, 품사, 번역 등의 정보를 포함함.
전처리
토큰화(Tokenization): 텍스트를 다른 입력 요소로 분리하는 프로세스
- 컴퓨터가 이해할수 있는 word level로 자름
벡터화: (Vectorization): 토큰을 숫자 표현으로 변환하는 프로세스
- 컴퓨터가 이해할 수 있도록 숫자로 표현
임베딩(Embedding): 의미관계, 문맥적의미등을 추가해 벡터표현을 개선함
- 비슷한 단어들을 비슷한 공간 벡터 안에 매핑함.
언어모델
언어 생성을 위한 딥러닝 모델을 선택함
- RNN, Transformer등
훈련
- 무작위 가중치로 모델을 초기화
- 아무것도 없는 상태로 만듦(Randomize)
- 학습 데이터를 모델에 공급하고, 예측값을 얻음
- 예측된 출력과 실제 목표 출력 간의 손실(오차) 계산
- 사용자가 원하는 output과의 오차를 파악
- 역전파 및 최적화 알고리즘을 사용해 모델의 가중치를 업데이트하고 손실을 최소화
- 전체 데이터 세트에 대해 2~4단계를 반복
- 모델이 높은 성능을 달성하거나 손실이 안정적이면 프로세스를 중단한다.
평가
난해성: 모델이 시퀀스에서 다음 단어를 얼마나 잘 예측하는가
이중 언어 평가 연구(BLEU) 점수: 생성된 텍스트와 하나 이상의 참조 텍스트 간의 유사성을 측정
주관적 평가: 사람이 평가
정성적 분석: 생성된 텍스트의 일관성, 문법, 문맥과 관련성을 수동으로 검사
작업별 지표: 작업에 따라 다른 지표를 사용(요약: ROUGE(생성된 요약, 참조요약간의 중첩 측정)
'학교공부 > 생성형 인공지능' 카테고리의 다른 글
| 6. BERT와 GPT (0) | 2025.10.12 |
|---|---|
| 5. 영상트랜스포머의 응용 (0) | 2025.10.09 |
| 4. 트랜스포머 및 Self Attention (1) | 2025.09.27 |
| 3. CNN(Convolution Neural Network) (0) | 2025.09.19 |
| 2. 재귀 신경망(RNN) (0) | 2025.09.10 |

