
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- TTS
- 머신러닝
- dementional reduction
- CNN
- 자연어처리
- 에이전트
- 정보처리기사
- RNN
- 기초
- python기초
- 트랜스포머
- RDBMS
- Transformer
- ASR
- 생성형 인공지능
- 딥러닝
- 알고리즘
- CLIP
- 데이터엔지니어
- UMAP
- Python
- 소프트웨어 개발
- 캐글
- python 기초
- 데이터 시각화
- LangGraph
- 객체지향
- 랭그래프
- SQL
- 힙정렬
- Today
- Total
수달이네 기술 블로그
9. 이미지 캡셔닝 본문
인코더-디코더 구조
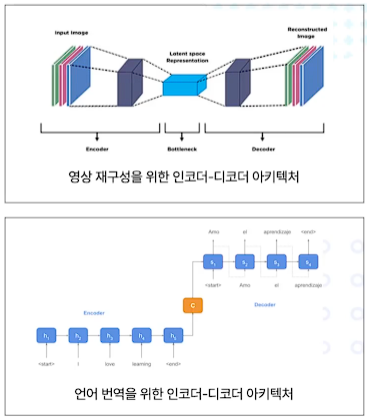
인코더, 디코더의 두 구조로 되어있는 모델
인코더 네트워크 : 입력의 표현, 컨텍스트를 생성(encoder > latent space > decoder)
디코더 네트워크: 문맥에 따라 출력을 생성
인코더
영상인코더
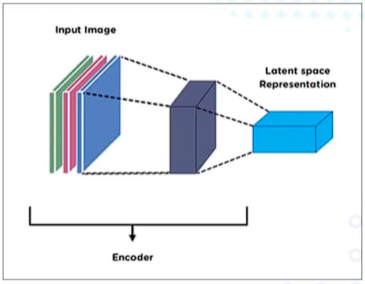
일반적으로 input image(입력 영상)를 convolution layer를 통해 feature(임베딩 벡터)를 추출
- 이젠 transformer로 대체
고정 크기의 임베딩 벡터를 임베딩, 잠재표현이라 한다.
일반적으로 CNN(convolution network)를 사용
최근엔 ViT(Vision transformer), PVT(pyramid vision transformer), swim을 많이 쓴다.
- 트랜스포머를 Convolution형식을 띄게 피라미드 형식으로 축소시키는 방식을 사용
- 목적에 따라 사용용도가 다름
언어인코더

일련의 단어, 토큰을 처리하여 숫자표현으로 변환 후 feature(임베딩 벡터)를 추출
- 이전엔 LSTM, GRU, RNN등이 사용됨.
- 최근엔 Bert 및 Transformer등의 Self-Attention모델이 크게 성공함.
영상 디코더

고정된 크기의 숫자표현을 입력으로 받고, 전체 해상도의 이미지를 생성한다.(Deconvolution)
- 이전에는 CNN(VAE/GAN)등을 사용했으나, 최근엔 트랜스포머, diffusion을 사용함.
언어 디코더
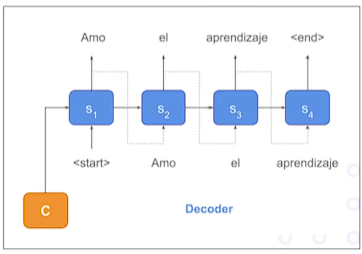
초기 상태를 취하고, 문맥, 입력정보를 기반으로 단어, 토큰의 시퀀스를 생성
- 최근엔 트랜스포머로 토큰을 병렬로 처리할 수 있음.
인코더 + 디코더

인코더와 디코더를 서로 다른 모달리티(영상, 언어, 등등)을 결합하면 다양한 애플리케이션을 제공 가능
- 이미지 캡션(영상 인코더-언어 디코더)
- 텍스트를 이용한 영상 생성(언어 인코더 - 영상 디코더)
- 시각적 질문 답벼냐(VQA): (영상 인코더, 언어 인코더 - 언어 디코더)
Feature Extraction(특징 추출)
특징 추출: 차원을 줄이고, 노이즈를 제거하여, 데이터의 가장 변별력 있는 측면을 강조 > 분석, 머신러닝에 이용

영상 내에서 Edge, texture, 모양등의 의미있는 시각적 요소를 압축
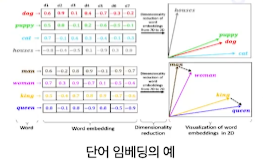
텍스트를 숫자 표현으로 변환하여 단어간의 의미관계 포착
Context vector생성
컨텍스트 벡터: 관련 정보를 간결하게 요약

글로벌 평균 풀링: 인코더가 공간차원에 걸쳐 생성한 모든 특징 맵의 평균을 취하여 그것의 컨텍스트 벡터를 찾음
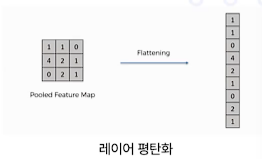
레이어 평탄화: pooled된 feature를 flattening하여 선형으로 만들어 디코더에서 추가 처리할 수 있도록 함.
컨텍스트 디코딩
- 컨텍스트 벡터의 의미를 찾아냄.
영상
- GAN or VAE같은 생성모델을 설정
- 컨텍스트 벡터는 생성기의 출력을 안내하는 역할 (생성된 이미지가 제공된 컨텍스트와 일치하고, 원하는 시각적 특성을 나타내게 함)
- 생성기는 컨텍스트 벡터와 가장 잘 일치하는 이미지를 생성해 인식 영상을 생성
언어
- RNN or Transformer기반 모델 설정
- 디코더는 시퀀스에서 이미 생성된 단어에 대한 예측을 조건으로 단어를 하나씩 예측
- 이과정에서 생성된 텍스트가 일관성있고, 문맥에 맞도록 유지함.
조건부 정보: 일부 작업에서 클래스 레이블, 텍스트 설명, 기타 컨텍스트와 같은 추가 정보에 따라 디코더를 조건부로 설정할 수 있다.
- 출력이 특정 기준, 제약조건에 부합하도록 보장한다.
Self-Attention 의 역할
정보 흐름 향상
- 인코더-디코더 아키텍처에서 동적 정보 필터 역할을 함.
- 특정 부분에 선택적 집중 > 관련성 높은 정보를 강조
시퀀스 간 작업 개선
- 소스 시퀀스와 타깃 시퀀스를 효과적으로 정렬해 번역 정확도를 개선, 문맥에 맞는 캡션을 생성함.
동적 컨텍스트화
- 디코딩 프로세스 중 초점을 적응적으로 조정해 각 출력요소에 대해 입력시퀀스의 다른 부분에 집중하도록 함. > 장거리 종속성 포착 + 일관성있도록 하여 모델의 능력 향상
손실 함수
언어 생성 작업에서 사용하는 손실함수는 Cross Entropy Loss(교차 엔트로피 손실)이다.
- 단어에 대한 모델의 예측 확률 분포, 실제 기준값 분포 간의 차이를 정량화

GAN, Auto Encoder같은 이미지 생성 작업에서 사용하는 손실함수는 Mean Square Error(MSE)이다.
- 생성 이미지와 기준 이미지 간의 픽셀 단위 불일치 측정

학습목표
언어 모델링 기계 번역 같은 텍스트 생성 작업의 경우의 목표는 Maximum Likelihood Estimation(최대 가능도 추정)이다.
- 가능성이 높은 시퀀스를 생성하도록 유도
평가
텍스트 생성 기계 번역은 BLEU, ROUGE등의 메트릭으로 평가
GAN등의 이미지 생성 작업은 시작점수 FID와 같은 매트릭으로 평가
영상 주석 생성

영상에 포함된 텍스트 캡션을 생성하는 작업
CNN과 같은 이미지 인코더 (이미지 임베딩) → RNN, 트랜스포머 등 언어 디코더(텍스트 생성)
구성요소
영상 인코더 : 임베딩 추출
언어 디코더: 텍스트 설명 생성
컨텍스트 벡터: 영상을 요약하는 숫자 표현
어텐션 메커니즘: 디코더가 캡션의 각 단어를 생성할 때 영상의 다른 부분에 집중할 수 있도록 함.
어휘, 언어모델: 사전정의된 단어, 토큰 어휘
평가지표: BLEU, ROUGE 등
응용처
시각장애인을 위한 시각 보조 도구

- 이미지에 대한 풍부한 텍스트 설명을 제공
이미지 기반 콘텐츠 색인 및 검색

- 텍스트를 통한 이미지를 검색
소셜미디어 콘텐츠 강화
- 인코더, 디코더 이미지 캡션으로 사용자가 생성한 컨텐츠를 풍부하게 만들고, 사용자 경험을 개선한다.
과제
정교한 물체 인식에 한계가 있다.
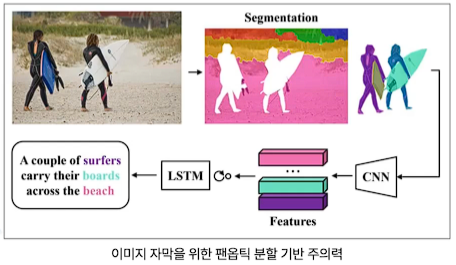
- 예를들어 위 사진을 보면 왼쪽 사람은 파란 보드를 들고 있고 이보드는 어디 제품이다, 이런 식의 인식
- 그렇기 때문에 위와 같이 새로운 기술을 계속 개발 중
장거리 종속성

위의 이미지의 각 물체간의 상관관계를 정확하게 기술하기엔 한계가 존재한다.
모호성 처리

위 이미지를 보면 하나의 객체를 표현하는 문장은 여러개이기 때문에 이걸 어떻게 표현하는가 가 문제
- 하나의 이미지에 대해 여러 유효 캡션이 존재할 가능성이 있음
'학교공부 > 생성형 인공지능' 카테고리의 다른 글
| 10. Text to Image(언어기반 영상 생성) + diffusion (0) | 2025.11.16 |
|---|---|
| 8. StyleGAN과 가짜 탐지 네트워크 (1) | 2025.10.29 |
| 7. 생성형 인공지능(GAN, VAE, Diffusion 모델 등) (0) | 2025.10.15 |
| 6. BERT와 GPT (0) | 2025.10.12 |
| 5. 영상트랜스포머의 응용 (0) | 2025.10.09 |